VLSA: Vision-Language-Action Models with
Plug-and-Play Safety Constraint Layer
2TetraBOT
3DAMO Academy, Alibaba Group
4Institute for Embodied Intelligence and Robotics, Tsinghua University
*Equal Contribution †Corresponding Author
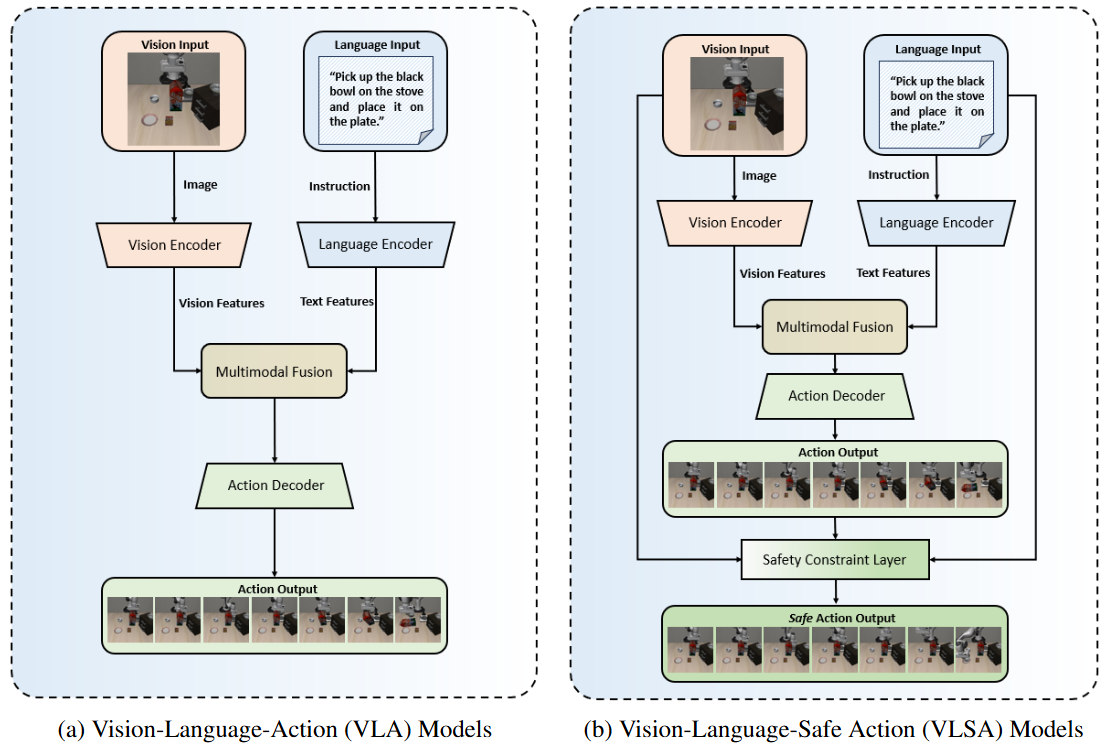
Figure 1: Functional architecture of VLA and VLSA models.
Overview
Vision-Language-Action (VLA) models have demonstrated remarkable capabilities in generalizing across diverse robotic manipulation tasks. However, deploying these models in unstructured environments remains challenging due to the critical need for simultaneous task compliance and safety assurance, particularly in preventing potential collisions during physical interactions.
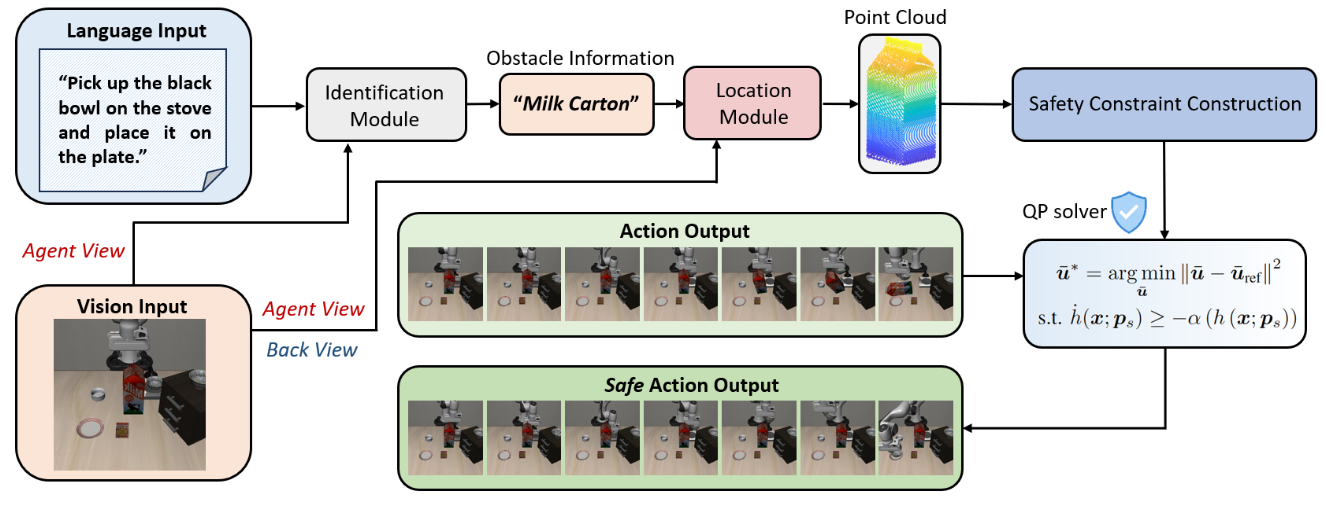
Figure 2: Workflow of the AEGIS model.
In this work, we introduce a Vision-Language-Safe Action (VLSA) architecture, named AEGIS, which contains a plug-and-play safety constraint (SC) layer formulated via control barrier functions. AEGIS integrates directly with existing VLA models to improve safety with theoretical guarantees, while maintaining their original instruction-following performance. To evaluate the efficacy of our architecture, we construct a comprehensive safety-critical benchmark SafeLIBERO. Extensive experiments demonstrate that AEGIS achieves:
We summarize the main contributions as follows:
- We propose AEGIS, the first approach that integrates CBFs into VLA models to enforce explicit safety constraints. By introducing a plug-and-play SC layer, AEGIS effectively addresses the limitation of end-to-end models regarding the lack of safety guarantees. Our approach has the potential to enhance the safety of any existing VLA model without the need for retraining.
- We design a vision-language based safety assessment module and an action-driven safety-guaranteed control module, which bridge visual perception and semantic understanding with safety-guaranteed control. By leveraging a CBF-QP solver, the safety of the adjusted actions is theoretically guaranteed.
- We establish SafeLIBERO, a comprehensive safety-critical benchmark derived from the LIBERO dataset, encompassing 32 diverse scenarios and 1600 episodes. Extensive experiments demonstrate that AEGIS achieves superior performance over state-of-the-art baselines.
Simulation Demonstrations
We compare OpenVLA-OFT, $\pi_{0.5}$, and Ours across 32 scenarios on our constructed benchmark.
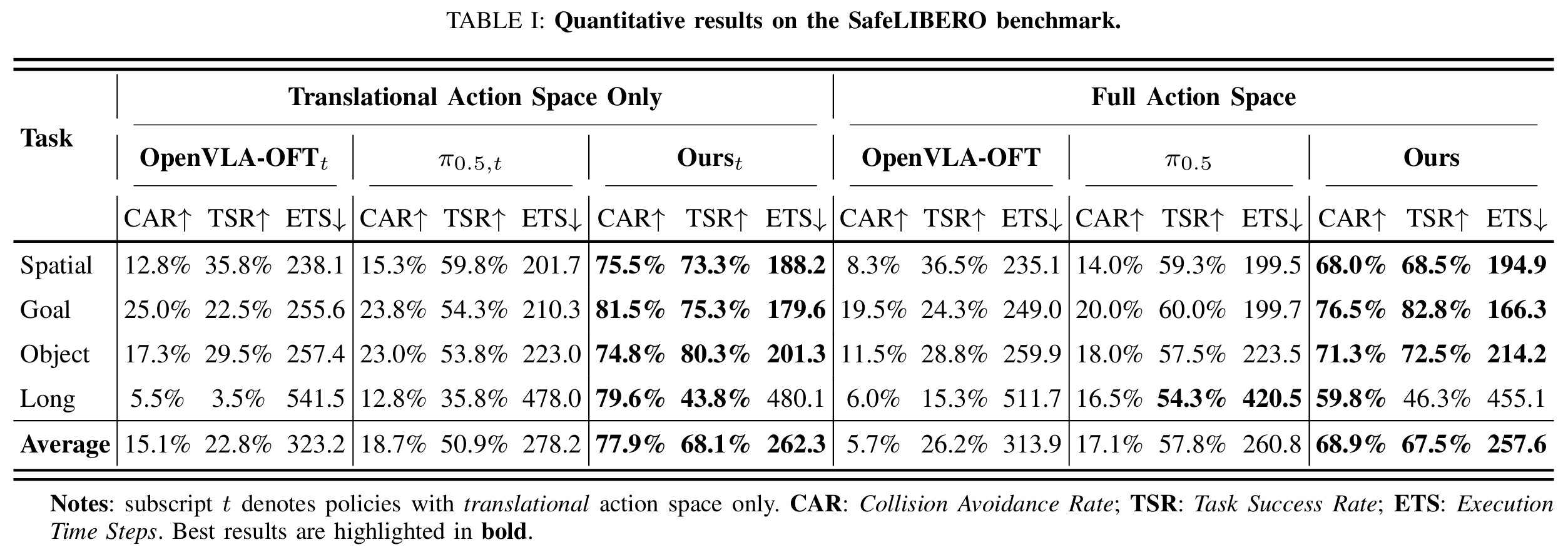
Note: To provide a comprehensive evaluation, we conduct experiments in both translational-only and full action space settings. We specifically include the translational setting given that SafeLIBERO tasks primarily involve top-down manipulation. This setting reduces action redundancy, allowing for a focused evaluation of positional collision avoidance capabilities.
Real-World Demonstrations
In our real-world experiments, we employ pi05-DROID as the base VLA policy. The robotic platform and evaluation tasks are illustrated in the following figure.

The platform consists of a 7-DoF Franka Emika Panda arm operated in joint velocity control mode, equipped with a Robotiq 2F-85 gripper. Perception is provided by an external ZED 2 stereo camera and a wrist-mounted ZED Mini stereo camera. The VLA policy infers at 15 Hz, while the low-level controller runs at 1 kHz. Experiments encompass two distinct tasks, each evaluated across two levels with varying obstacles.
Baseline
Ours (AEGIS)
BibTeX
@misc{hu2025vlsavisionlanguageactionmodelsplugandplay,
title={VLSA: Vision-Language-Action Models with Plug-and-Play Safety Constraint Layer},
author={Songqiao Hu and Zeyi Liu and Shuang Liu and Jun Cen and Zihan Meng and Xiao He},
year={2025},
eprint={2512.11891},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2512.11891},
}